PDF] Mastering Chess and Shogi by Self-Play with a General
Por um escritor misterioso
Last updated 22 dezembro 2024
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/38fb1902c6a2ab4f767d4532b28a92473ea737aa/4-Figure1-1.png)
This paper generalises the approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains, and convincingly defeated a world-champion program in each case. The game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. In contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go, by tabula rasa reinforcement learning from games of self-play. In this paper, we generalise this approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains. Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://miro.medium.com/v2/resize:fit:904/1*inE3Mx272f85QrpEUdkxVw.jpeg)
Is AlphaZero really a scientific breakthrough in AI?, by Jose Camacho Collados
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://i.ytimg.com/vi/xV9XnhfBCTA/hq720.jpg?sqp=-oaymwEhCK4FEIIDSFryq4qpAxMIARUAAAAAGAElAADIQj0AgKJD&rs=AOn4CLDxg9FjtQo0Sm8_ZRmgkuv59iTbBQ)
Outrageous Artificial Intelligence: (Game 7) : DeepMind's AlphaZero crushes Stockfish Chess Engine
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://image.slidesharecdn.com/alphazeropresentationjournalclub-190811050615/85/alphazero-a-general-reinforcement-learning-algorithm-that-masters-chess-shogi-and-go-through-selfplay-6-320.jpg?cb=1668399516)
AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/071e11e5845e72466bb8fbdc617d45c4d83e7b0a/2-Figure1-1.png)
PDF] The Chess Transformer: Mastering Play using Generative Language Models
PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://www.researchgate.net/profile/Timothy_Lillicrap/publication/321571298/figure/fig1/AS:568407281147904@1512530264876/Training-AlphaZero-for-700-000-steps-Elo-ratings-were-computed-from-evaluation-games_Q320.jpg)
PDF) Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://image.slidesharecdn.com/alphazeropresentationjournalclub-190811050615/85/alphazero-a-general-reinforcement-learning-algorithm-that-masters-chess-shogi-and-go-through-selfplay-2-320.jpg?cb=1668399516)
AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://cdn.slidesharecdn.com/ss_thumbnails/2hx8ocb1rtcxjhaovfpi-signature-b1dc8307ff83e0affd0e6d40dd8135771d7c5ec340fb5905f7839d4662d32112-poli-171219170402-thumbnail.jpg?width=640&height=640&fit=bounds)
AlphaZero
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://0.academia-photos.com/attachment_thumbnails/56304303/mini_magick20190112-3572-1au4sv0.png?1547325954)
PDF) Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/38fb1902c6a2ab4f767d4532b28a92473ea737aa/7-Figure2-1.png)
PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://upload.wikimedia.org/wikipedia/commons/thumb/0/0b/Furigoma.jpg/220px-Furigoma.jpg)
Shogi - Wikipedia
Recomendado para você
-
 New AlphaZero Paper Explores Chess Variants22 dezembro 2024
New AlphaZero Paper Explores Chess Variants22 dezembro 2024 -
 AlphaZero, Vladimir Kramnik and reinventing chess22 dezembro 2024
AlphaZero, Vladimir Kramnik and reinventing chess22 dezembro 2024 -
 Deepmind's AlphaZero Plays Chess22 dezembro 2024
Deepmind's AlphaZero Plays Chess22 dezembro 2024 -
 Multiplayer AlphaZero22 dezembro 2024
Multiplayer AlphaZero22 dezembro 2024 -
 DeepMind's AlphaGo Zero and AlphaZero22 dezembro 2024
DeepMind's AlphaGo Zero and AlphaZero22 dezembro 2024 -
 Question on the Alpha Zero research paper : r/chess22 dezembro 2024
Question on the Alpha Zero research paper : r/chess22 dezembro 2024 -
 AlphaGo - How AI mastered the hardest boardgame in history22 dezembro 2024
AlphaGo - How AI mastered the hardest boardgame in history22 dezembro 2024 -
 Contributing to Leela Chess Zero. Creating the Caissa of Chess engines. - Leela Chess Zero22 dezembro 2024
Contributing to Leela Chess Zero. Creating the Caissa of Chess engines. - Leela Chess Zero22 dezembro 2024 -
AlphaZero: Shedding new light on chess, shogi, and Go - Google DeepMind22 dezembro 2024
-
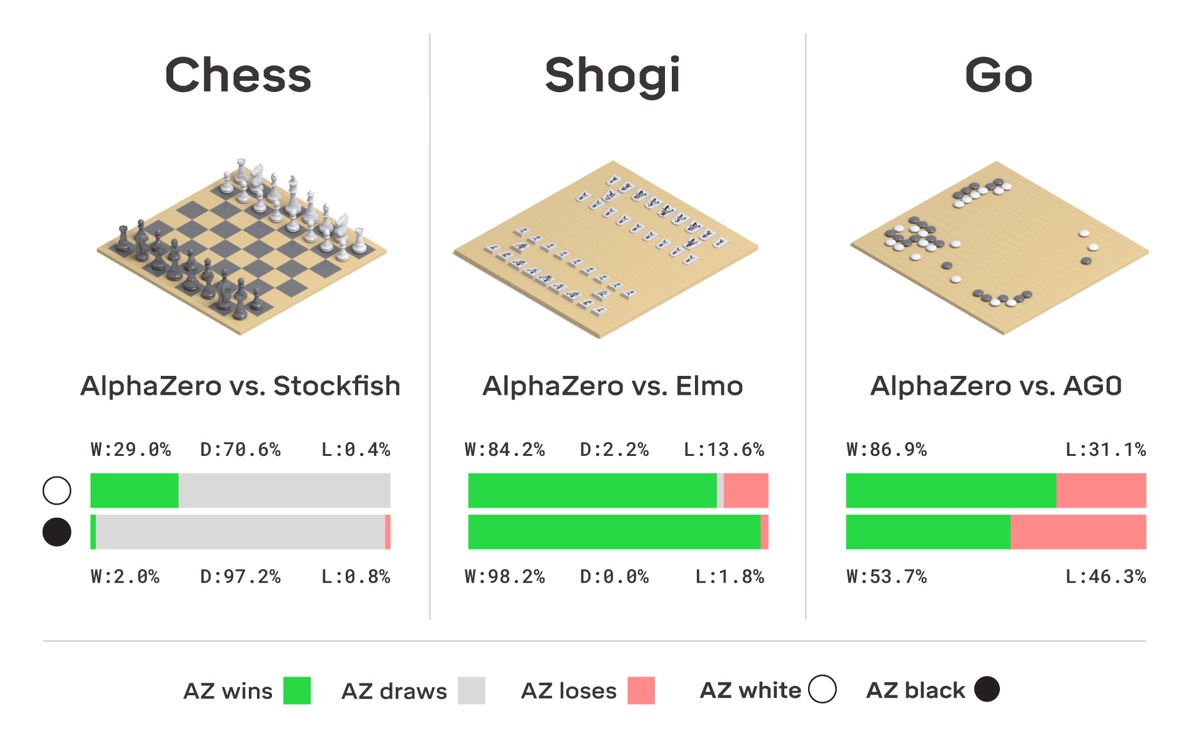 Move over AlphaGo: AlphaZero taught itself to play three different games22 dezembro 2024
Move over AlphaGo: AlphaZero taught itself to play three different games22 dezembro 2024

você pode gostar
-
 colherzinha para brigadeiro personalizada roblox menina22 dezembro 2024
colherzinha para brigadeiro personalizada roblox menina22 dezembro 2024 -
Houston Pets Alive22 dezembro 2024
-
 boca gacha tela verde para edit22 dezembro 2024
boca gacha tela verde para edit22 dezembro 2024 -
 Blood Lad Official Files - Dark Hero Rising Guide Book22 dezembro 2024
Blood Lad Official Files - Dark Hero Rising Guide Book22 dezembro 2024 -
 Labetalol Hydrochloride Tablets, USP Rx only22 dezembro 2024
Labetalol Hydrochloride Tablets, USP Rx only22 dezembro 2024 -
 Sky High Disney Movies22 dezembro 2024
Sky High Disney Movies22 dezembro 2024 -
 Bolos simples e fáceis de fazer para o café da tarde22 dezembro 2024
Bolos simples e fáceis de fazer para o café da tarde22 dezembro 2024 -
 GM / MONTANA LS 1.4 – Cabeção Automóveis22 dezembro 2024
GM / MONTANA LS 1.4 – Cabeção Automóveis22 dezembro 2024 -
O Sonic feio não ia estar no Filme! #sonic #fypシ #desenho22 dezembro 2024
-
 Uma identidade “molenga” para Nike Kids abraça a maneira de brincar das crianças – Clube MIS22 dezembro 2024
Uma identidade “molenga” para Nike Kids abraça a maneira de brincar das crianças – Clube MIS22 dezembro 2024

