PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Por um escritor misterioso
Last updated 03 janeiro 2025
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://d3i71xaburhd42.cloudfront.net/38fb1902c6a2ab4f767d4532b28a92473ea737aa/4-Figure1-1.png)
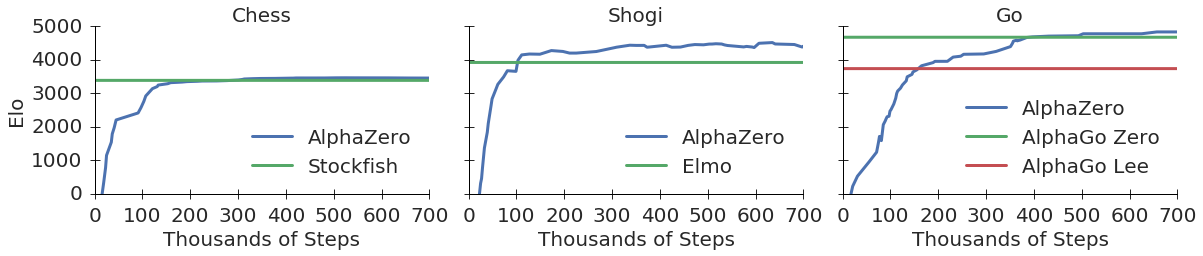
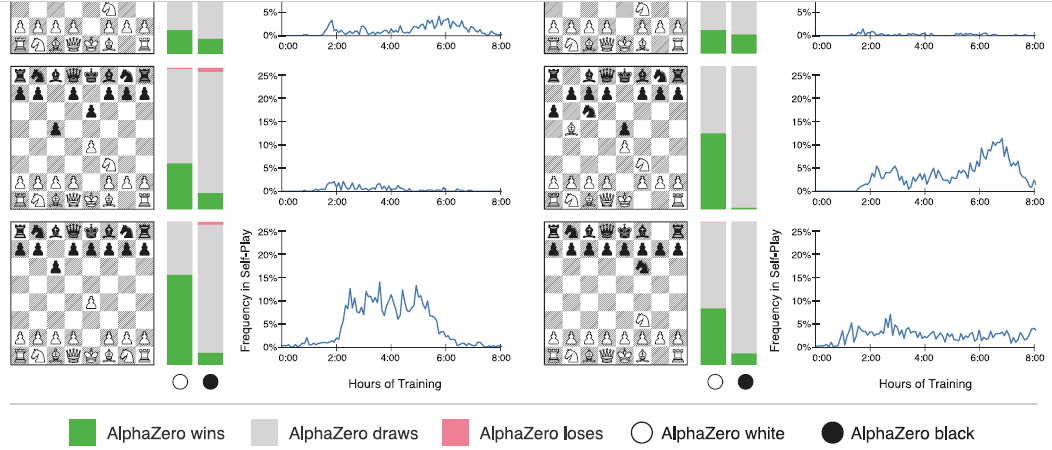
This paper generalises the approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains, and convincingly defeated a world-champion program in each case. The game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. In contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go, by tabula rasa reinforcement learning from games of self-play. In this paper, we generalise this approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains. Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://image.slidesharecdn.com/alphazeropresentationjournalclub-190811050615/85/alphazero-a-general-reinforcement-learning-algorithm-that-masters-chess-shogi-and-go-through-selfplay-4-320.jpg?cb=1668399516)
AlphaZero: A General Reinforcement Learning Algorithm that Masters Chess, Shogi and Go through Self-Play
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://blog.acolyer.org/wp-content/uploads/2018/01/alphazero-table-s1.jpeg?w=520)
Mastering chess and shogi by self-play with a general reinforcement learning algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://0.academia-photos.com/attachment_thumbnails/72944652/mini_magick20211017-17085-nissjc.png?1634489922)
PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://d3i71xaburhd42.cloudfront.net/02b4fb7cc30e18022678314cfecc350a821d1fb2/6-Figure3-1.png)
PDF] Reinforcement Learning for Extended Reality: Designing Self-Play Scenarios
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://www.science.org/cms/10.1126/science.aar6404/asset/52d0f7b2-dc89-4dfb-b5fe-bdfa61fbc4b6/assets/graphic/362_1140_f2.jpeg)
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://community.cadence.com/resized-image/__size/640x0/__key/communityserver-blogs-components-weblogfiles/00-00-00-01-06/7776.azshot.jpg)
AlphaZero: Four Hours to World Class from a Standing Start - Breakfast Bytes - Cadence Blogs - Cadence Community
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://www.researchgate.net/profile/Timothy_Lillicrap/publication/321571298/figure/fig1/AS:568407281147904@1512530264876/Training-AlphaZero-for-700-000-steps-Elo-ratings-were-computed-from-evaluation-games_Q320.jpg)
PDF) Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://media.springernature.com/full/springer-static/image/art%3A10.1038%2Fnature16961/MediaObjects/41586_2016_BFnature16961_Fig1_HTML.jpg)
Mastering the game of Go with deep neural networks and tree search
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://d3i71xaburhd42.cloudfront.net/4c7028640e3470a73af84d22eafa78855931c70f/21-Figure3-1.png)
PDF] Giraffe: Using Deep Reinforcement Learning to Play Chess
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://upload.wikimedia.org/wikipedia/commons/thumb/9/9f/Shogiban.png/300px-Shogiban.png)
Shogi - Chessprogramming wiki
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://miphidic.files.wordpress.com/2017/12/deepmindchess1.jpg?w=770&h=380)
Deepmind's AlphaZero Plays Chess
![PDF] Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm](https://media.springernature.com/m685/springer-static/image/art%3A10.1038%2Fs41586-020-03051-4/MediaObjects/41586_2020_3051_Fig2_HTML.png)
Mastering Atari, Go, chess and shogi by planning with a learned model
Recomendado para você
-
 AlphaZero really is that good03 janeiro 2025
AlphaZero really is that good03 janeiro 2025 -
 AlphaZero Explained03 janeiro 2025
AlphaZero Explained03 janeiro 2025 -
 AlphaZero - Notes on AI03 janeiro 2025
AlphaZero - Notes on AI03 janeiro 2025 -
 Inside the (deep) mind of AlphaZero03 janeiro 2025
Inside the (deep) mind of AlphaZero03 janeiro 2025 -
 AlphaZero - Chessprogramming wiki03 janeiro 2025
AlphaZero - Chessprogramming wiki03 janeiro 2025 -
 Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop03 janeiro 2025
Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop03 janeiro 2025 -
 DeepMind: the existence proof for RL at scale, by Nathan Lambert03 janeiro 2025
DeepMind: the existence proof for RL at scale, by Nathan Lambert03 janeiro 2025 -
AlphaZero: Shedding new light on chess, shogi, and Go - Google DeepMind03 janeiro 2025
-
 Move over AlphaGo: AlphaZero taught itself to play three different03 janeiro 2025
Move over AlphaGo: AlphaZero taught itself to play three different03 janeiro 2025 -
 Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play03 janeiro 2025
Policy or Value ? Loss Function and Playing Strength in AlphaZero-like Self-play03 janeiro 2025

você pode gostar
-
 SAIBA O SIGNIFICADO DO ANEL DE ITACHI UCHIHA NA AKATSUKI - GUIA COMPLETO03 janeiro 2025
SAIBA O SIGNIFICADO DO ANEL DE ITACHI UCHIHA NA AKATSUKI - GUIA COMPLETO03 janeiro 2025 -
 Watch Angels of Death Episode 1 Online - Kill me please.03 janeiro 2025
Watch Angels of Death Episode 1 Online - Kill me please.03 janeiro 2025 -
 Infinite Saiyans, Ultra Dragon Ball Wiki03 janeiro 2025
Infinite Saiyans, Ultra Dragon Ball Wiki03 janeiro 2025 -
Mine Blocks Stuffs03 janeiro 2025
-
 RASenha #5 — Maze Runner - Correr ou Morrer (filme)03 janeiro 2025
RASenha #5 — Maze Runner - Correr ou Morrer (filme)03 janeiro 2025 -
 ProVolver haptic pistol : feel the recoil for your Meta Oculus03 janeiro 2025
ProVolver haptic pistol : feel the recoil for your Meta Oculus03 janeiro 2025 -
Hungry Snake - Cobra – Apps no Google Play03 janeiro 2025
-
 5 curiosidades sobre Tico e Teco, a dupla mais encrenqueira da Disney03 janeiro 2025
5 curiosidades sobre Tico e Teco, a dupla mais encrenqueira da Disney03 janeiro 2025 -
RichPresence for Discord03 janeiro 2025
-
 Roblox The Application Encountered An Unrecoverable Error Fix (2023)03 janeiro 2025
Roblox The Application Encountered An Unrecoverable Error Fix (2023)03 janeiro 2025